Since its discovery a few decades ago, the Kelly criterion has become a reference for professional gamblers and speculators alike. This very simple formula calculates the fraction of risk capital which should be allocated on a single bet in order to maximise long term wealth. But, can this approach be extended to the case of simultaneous independent bets which are quite common in investing or sports betting? In this short piece, we will look into a numerical method to calculate the optimal risk allocation across multiple bets based on Kelly's approach, and run through an intuitive analysis of the results.
Kelly criterion
In 1956, John Larry Kelly, Jr, a researcher at Bells Lab, discovered a simple formula for the optimal fraction of risk capital that should be waged on a particular bet, in order to maximise wealth over the long run. His formula is derived by maximising the expectation of the logarithm of the final wealth:
$$ \mathbf{E} (f;p,b) = p \ln(1 + fb) + (1 - p) \ln(1 - f) $$
where \( p \) is the probability of winning the bet, \( b \) are the net fractional odds or profit-to-loss ratio, and \( f \) the fraction of wealth to be waged. Using basic calculus, the optimal allocation \( f^{*} \) comes out as:
$$ f^{*} = \underset{f}{\operatorname{argmax}} \mathbf{E} (f;p,b) = \dfrac{p(b+1) - 1}{b} $$
This famous formula, called the Kelly Criterion, took the speculating world by storm probably due to its simplicity and elegance. But what happens when we would like to take part in several simultaneous independent bets? Is the optimal allocation across our portfolio of bets equivalent to the optimal allocation calculated on every single bet? It would be very convenient, but unfortunately, this is not the case. Let's get into the multiple bets case in more detail.
Simultaneous independent bets in the Kelly framework
The expectation of the log of the final wealth after 2 simultaneous independent bets can be expressed as:
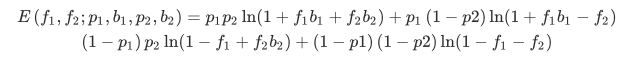
In the case of two bets, solving for \( f_1 \) and \( f_2 \) algebraically is clearly more time consuming to achieve than for the single bet case. Even if the solving process ultimately narrows down to a straightforward system of 2 linear equations with 2 constrained unknowns variables, characterising such a system for an arbitrary number of bets is not simple. A numerical approach is far more appealing especially as the gradient of the objective function can be easily calculated. Going down the numerical route, first involves coding a function that would return the expectation of the log of the final wealth and its gradient for any number of independent simultaneous bets. Here is its implementation in the Rust programming language:
use ndarray::prelude::*;
use itertools::Itertools;
pub fn multiple_simultanous_expectation_log_wealth( bets_data: &Vec<(f64,f64)>, fs: &Vec<f64>) -> (f64, Vec<f64>) {
assert_eq!( bets_data.len(), fs.len() );
let mut res = 0f64;
let mut grad = DVector::from_element(bets_data.len(), 0f64);
for indices in std::iter::repeat(0).take(bets_data.len()).map(|i| i..i+2).multi_cartesian_product() {
let mut prob = 1f64;
let mut wealth = 1f64;
let mut local_grad = DVector::from_element(bets_data.len(), 0f64);
for (i, &j) in indices.iter().enumerate() {
if j == 0 {
prob *= bets_data[i].0;
wealth += fs[i] * bets_data[i].1;
local_grad[i] += bets_data[i].1;
} else {
prob *= 1f64 - bets_data[i].0;
wealth -= fs[i];
local_grad[i] -= 1f64;
}
}
if wealth > 0f64 {
res += prob * wealth.ln();
grad += &(prob * &local_grad / wealth);
}
}
(res, grad.as_slice().into())
}
Then an optimisation routine for maximising the function armed with its gradient has to be used. The Gradient Ascent algorithm seems to be a natural fit for this role. However, respecting the bounds constraining the variables while performing an iterative optimisation is really where approximations are made. At each iteration, a clipping function forces each wager value between 0 and 1. If the sum of all calculated wagers is greater than 1, a scaling factor is applied homogeneously on all wagers to get their sum back to 1. Here is its implementation using the previously defined function:
// Returns a value comprised between 0 and 1
pub fn clip(x: f64) -> f64 {
if x > 1f64 {
1f64
} else if x < 0f64 {
0f64
} else {
x
}
}
pub fn multiple_simultaneous_kelly(bets_data: &Vec<(f64,f64)>, alpha: f64, max_iter: usize) -> (f64, Vec<f64>) {
let mut value_var = 0f64;
let mut fs_var = vec![0f64; bets_data.len()];
for _ in 0..max_iter {
let (value, grad) = multiple_simultanous_expectation_log_wealth( &bets_data, &fs_var );
let mat = DVector::from_row_slice(fs_var.as_slice()) + DVector::from_row_slice(grad.as_slice()) * alpha;
let mut fs_candidate = mat.iter()
.map(|&x| clip(x))
.collect::<Vec<f64>>();
// Scale weights if total greater than 1
let total : f64 = fs_candidate.iter().sum();
if total > 1f64 {
for x in fs_candidate.iter_mut() {
*x = *x / total;
};
}
// Stop if no improvement in expectation
let (value_candidate, _) = multiple_simultanous_expectation_log_wealth( &bets_data, &fs_candidate);
if value_candidate <= value {
break;
} else {
fs_var = fs_candidate;
value_var = value_candidate;
}
}
(value_var, fs_var)
}
Using this approach, let's try and get an intuitive understanding of the results for a specific example.
Sequential vs Simultaneous
Let's consider a portfolio of 7 simultaneous bets with positive edge. The table below states each bet's characteristics, its individual Kelly criterion and the optimal wager numerically calculated.
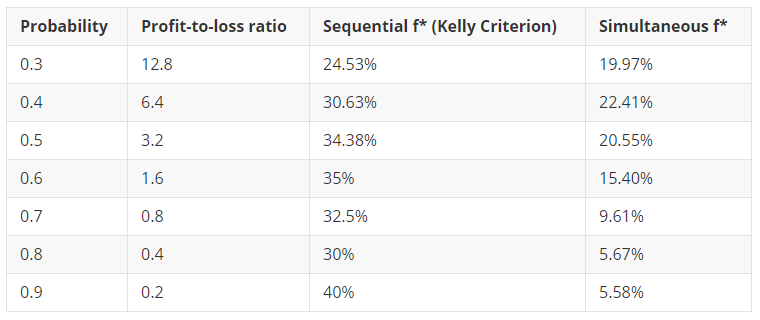
We observe that the optimal wagers calculated are smaller than the Kelly Criteria (Sequential bets) in absolute terms. Surprisingly, in the simultaneous setting, the distribution of the optimal wagers across bets is drastically different from the distribution in a sequential setting. How could this be the case?
Probabilistic Edge
The paper Algorithms for optimal allocation of bets on many simultaneous events - C. Whitrow (2007) documented an attempt to gain some understanding on the distribution of the optimal wagers in the case of multiple simultaneous and independent bets. A very interesting observation was made on this topic: For a large number of bets, the optimal wagers tend to be proportional to the "probabilistic edge" of each bet
$$ \text{Probabilistic edge} = p - \dfrac{1}{b + 1} $$
The validity of result is very apparent in our example, as the chart below illustrates:
The paper's author investigated the exact mathematical relationship between these quantities using regression, but unfortunately, failed to bring any intuitive explanation as to why such relationship exists.
Conclusion
The decades-old approach developed by J.L.Kelly Jr, to optimally allocate risk capital on a single bet, is easily extendable to a multiple simultaneous bets situation thanks to numerical optimisation methods. However, it is important to mention that optimising long term returns is only one aspect of the risk allocation process. The other is to minimise the risk-of-ruin which is crucial for financial survival when bad luck strikes. Hence the optimal approach for capital allocation is a trade off between these two metrics. Risk preferences do play a big role in this process, turning risk capital allocation into a very subjective exercise. For these reasons, Kelly's wagers tend to be used as references only, helping speculators getting to an allocation fitting their specific risk appetite.
A demo implementation of this solver is available to use on the website.
If you like this post, follow me on Twitter and get notified on the next posts.